As a Software Engineering Manager and VP of Engineering/Operations, I have observed different socio-technical systems and ways organizations route software defects that customers report to the development teams. I want to share some of the options I met in mid-to-large companies (12+ development teams) and share my observations regarding the trade-offs they offer. But first, let's see the problem we're trying to solve.
We're in the context of having a customer who reports a defect in the product. They may do it via different channels (email, telephone, chat, a customer portal, etc.), but eventually, this will be stored in a work/issue tracker (i.e., JIRA).
Customers want two things related to these reported defects: to have them fixed as soon as possible and not to face the same or a similar problem in the future.
How organizations route an issue/case/ticket to the team that will fix it impacts the time it takes to resolve the issue. Routing is trivial when the company is small, but figuring out who has to fix something can be challenging when your organization has more than a dozen development teams.
The impact of routing to the wrong team
What's the impact of routing the issue to the wrong team? The answer is that it depends. At a bare minimum, when we route it to the wrong team, we know we will take longer to fix the problem than if we were routed to the right team. We're also adding more work to a team that will eventually reroute the issue to the right team.
If we focus only on maximizing customer value, we would like issues immediately assigned to those who can fix them. We don't want people in the middle, as they will not be doing high-leverage work, and issues will take longer to solve.
There are many reasons why companies might not attempt to send issues straight to engineers who can solve them, as there are other constraints that might make it unpractical in terms of costs, scalability, service quality, etc.
Now, let's look at the different ways I've seen companies set their processes and organizational structure to handle customer-reported defects. We'll start with a baseline system (#0) and see its pitfalls. Then, we'll see others I have worked with and review the problems they aim to address and the new issues they introduce.
System #0: All teams polling from the pool of defects
In this model, customers report issues through a system that feeds an issue tracker. Each development team is responsible for a specific part of the code. By code, it could be either a set of modules on a modular architecture or a whole code base or service.
Each team is responsible for polling the issue tracking system and figuring out which defects are related to the scope of the product they own. They are also responsible for fixing those issues and handling communication with the customer (such as asking clarifying or follow-up questions and getting confirmation that the problem was solved).
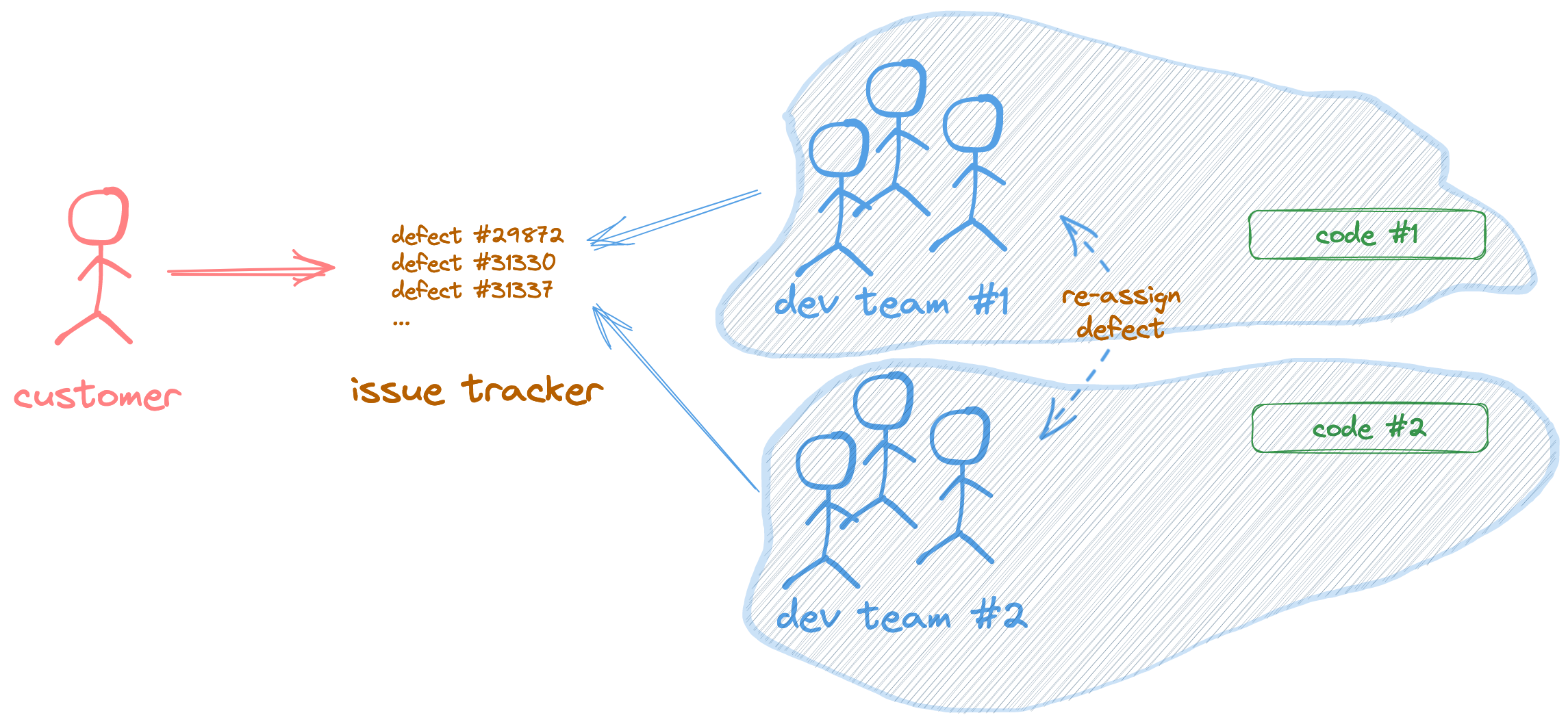
This model is a simple collaborative model to handle defects. It might be the starting point for some small companies or startups, but it has some drawbacks in cost and time efficiency as soon as the number of users or the number of development teams grows.
What's good about System #0?
This system aims to reduce the time to resolve an issue. When a customer reports a defect, it will be seen by the people who can fix it and tackle it promptly. Whether the development team interrupts what they are doing to handle the defect or waits to finish a task before tackling it is up to the team.
Note: I will discuss team dynamics in a follow-up article.
Another good thing about this model is that the team that builds features for the code is the one handling the defect related to that code. That also means engineers will take less time to solve the defect than if they were unfamiliar with the code. Additionally, knowing the code's problems is a great feedback loop for the team. They can use this feedback to improve their development practices further.
The reasons why System #0 does not scale
Although it has some virtues we're looking for, as companies grow, they seldom use this model.
Cost efficiency: Engineers might not be the best first-line of customer support. Many reported defects are not related to bugs in the software but just knowledge gaps about the product's capabilities that another power user could resolve. Although it is possible to have your Engineers reply to all those questions, there is an opportunity to have other roles handle those cases and to try to let your (expensive) Engineers focus on doing development work by only submitting those cases that are bugs to the development teams.
Small team constraints: We usually design our software teams to be small enough to be fed by two pizzas. Given this constraint, there is a maximum amount of issues that the team would be able to process. When the product succeeds and scales the number of users, the number of support requests will also grow. There is a limit to how much support work a small development team can tackle.
It is inefficient to have every team polling the issue tracker: As the organization grows, you will have both a larger number of support requests and more developers who are hired and organized in more development teams. Having each team monitor the whole list of issues is very inefficient as they have to try to find which issues are related to theirs in a larger bucket, and not only that, every team is wasting time on the same task.
Occasional delays due to lack of Accountability: Eventually, as we have many teams and a more extensive list of reported defects, some teams will fail to recognize which bugs are theirs. Those bugs are going to stay on the list for a longer time until someone claims them or there is a customer escalation.
Customer communications skills: Customers might need some back and forth until they can adequately report a reproducible defect by the team. Effectively handling communications requires soft skills that might not be present in all software engineers. If finding and hiring a developer is hard, hiring developers who can effectively manage customer relationships and communication will be even more challenging (and expensive).
Teams can sometimes lose focus on feature work. Another challenge of this model is that development teams must balance the work in solving customer defects with other activities such as feature development and technical debt.
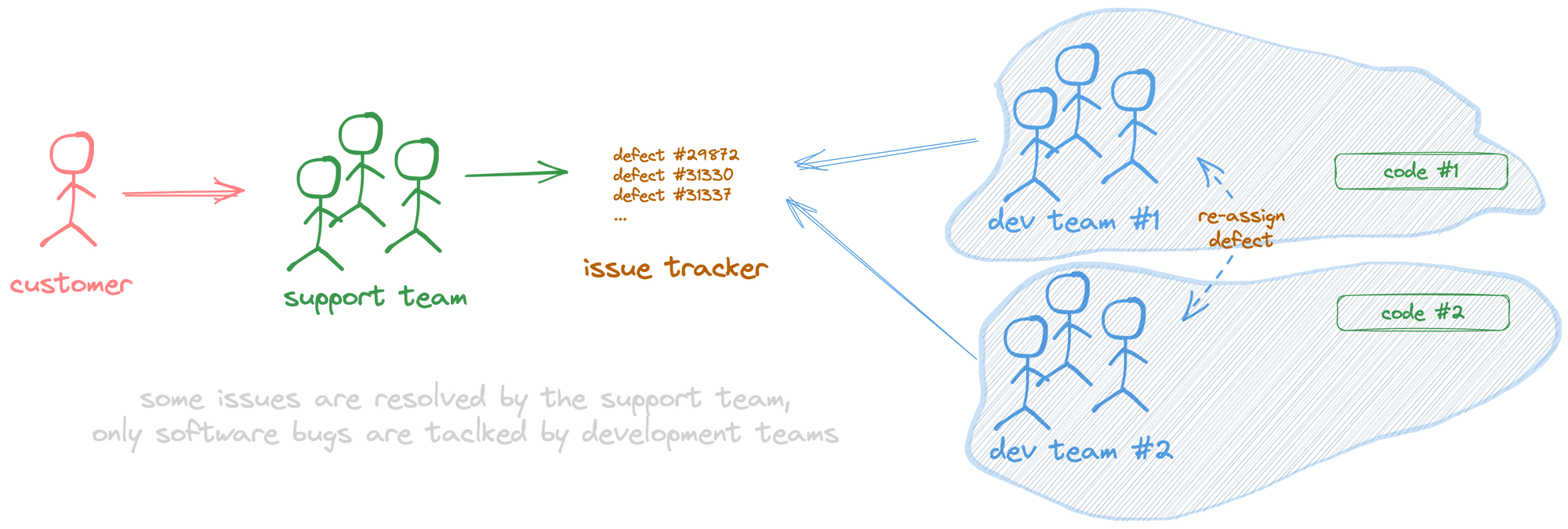
Why include a Support team? (and why do most companies have one?)
Support teams are a response to some of the problems mentioned above. You can hire non-engineers with good people skills and train them to know your product well. They can provide support to your customers and delegate to the development teams only the cases that are software bugs.
In that sense, they can handle the back and forth between the customer and the company to understand the problem and solve those support requests related to how the customer is using or configuring the product and are not software bugs. At the same time, you can hire people with good soft skills who can provide better communication and service to the customer. These can be scaled independently from the development team.
At last, Support teams can handle additional communication channels such as chat or phone.
We can say that a support team aims to improve cost efficiency, remove small team constraints, and provide superior customer communication skills.
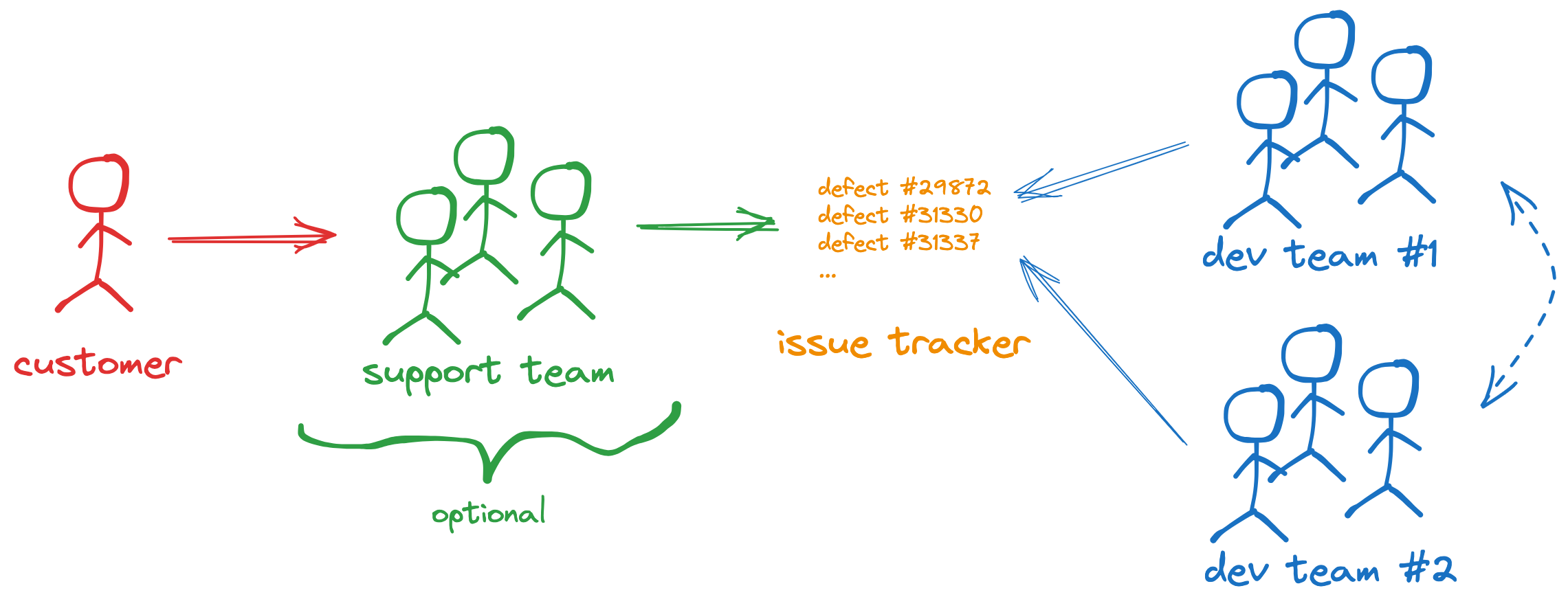
System#1: The support team assigns the work directly to a development team
This model (Figure 1) has a support team between the customer and the development team. This team is trained in the product, handles customer communication, and can solve product knowledge gaps. They submit or route software bugs to the development team that owns the functionality. They can do this because they know the product and which team owns each part of the product.
Each ticket is assigned to a team. The team will always analyze it; if it has to route it to another team, it will do it internally by providing additional information about why it was routed.
What's good about System #1?
This model aims to solve some of the weaknesses of scaling system #0. First, we get all the benefits of adding a support team (mentioned above). Additionally, by having the support team assign the ticket to a development team, this model eliminates the need for being inefficient due to having every team polling the issue tracker and avoiding occasional delays due to lack of Accountability.
All these are done by keeping the benefits of System #0 of having each team own a part of the code and getting feedback from their customers.
The potential downsides of System #1
One of the potential downsides of System #1 is having an intermediary between the customer and the development team. While I think this, in general, is not a downside, as many times Support teams can provide faster support for issues they know how to handle, there are times when a member of the support team may fail to identify the correct development team, or figuring out the proper steps to reproduce an issue. While those cases could also happen in System #0, having an intermediary also adds some time to resolve those issues.
System #2: On-duty defect rotation
In this model, we take a few engineers from different development teams to form a group that will analyze and solve all incoming defects over a given period (like daily or weekly). Then, another group of engineers picks it up for the following period, and so on.
These engineers are temporarily assigned to the rotation and are responsible for fixing all defects, no matter which teams initially built or wrote the code.
The support team is optional.
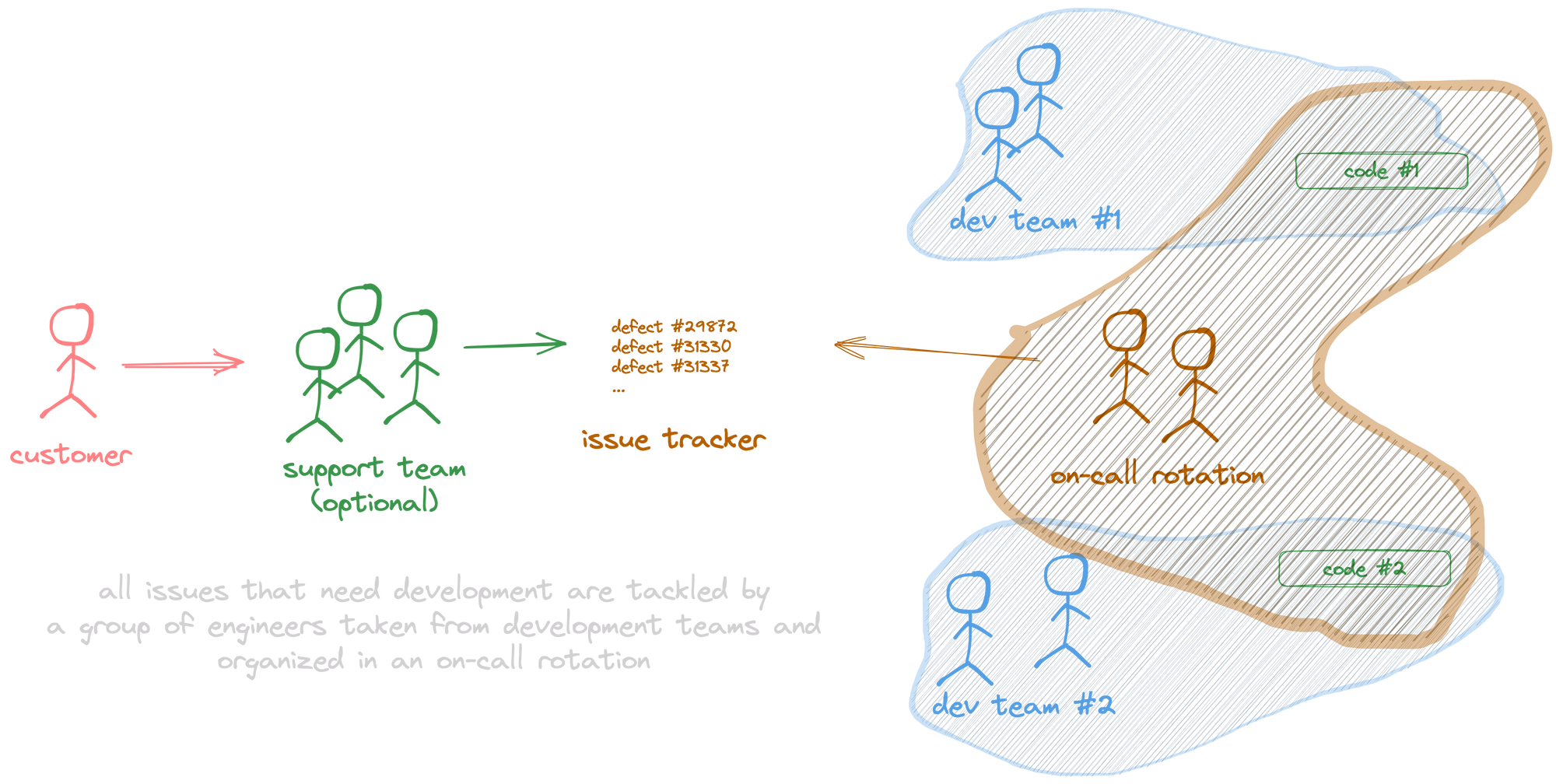
What's good about System #2?
Teams and organizations that embrace this model are looking for more predictability over the flow of feature work by allowing development teams to focus on feature work.
They also get almost all the benefits for System #1, except for the feedback loop, which is less consistent (although engineers might be able to see across the issues and propose good practices).
This model is used more in service companies that develop software for a 3rd party and in companies that embrace a factory-like process mentality.
What's the trade-off of this model?
This model usually adds more time to solve an issue. As there is a rotation, developers do not always know the code and functionality they are supposed to fix. Additionally, for the successful adoption of this model, more additional steps or support might be required from the team that owns the code or built the feature in the first place.
This model also separates the queue of customer-reported defects from feature development and other types of work. This has implications for how work is prioritized, tackled, and prioritized. For instance, if there is an unexpected surge of reported defects, the on-call team can prioritize and attack those that are more critical first without interrupting feature work. On the other side, this could take non-critical issues longer to be resolved.
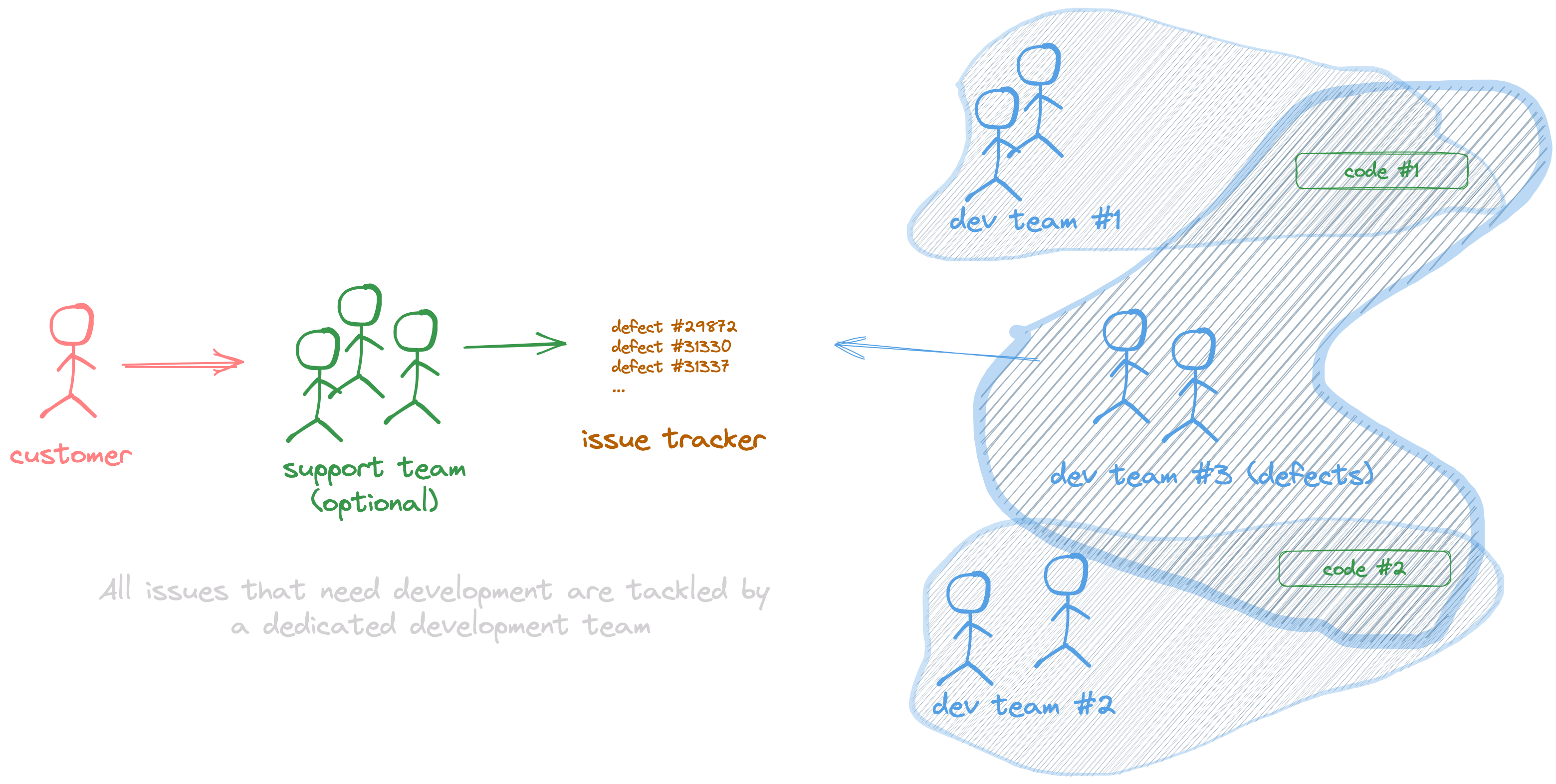
System #3: Dedicated maintenance team
This is a variation of System #2 in which, instead of having a rotating team, we have a dedicated team solely focused on fixing customer-reported defects for all code.
What's good about System #3?
The system gets the benefits and issues from the previous model by separating the feature and maintenance work in two different queues, each with its own capacity and focus.
Having a specific team just for handling defects can also make setting up good practices easier. In general, it is easier to align a small team than a distributed team in terms of development practices (i.e., all bugs need to be covered by a unit test), processes (i.e., SLAs), and communication practices (i.e., provide an RCA in every ticket).
Also, in terms of cost optimization, when you centralize a function, you can have a higher team allocation to that function. This means that if your team is cross-functional, they will perform many different tasks, and sometimes, a developer might not have any development to do but will be focused on reviewing a specification, doing an analysis, or releasing something. But when a function such as handling defects is centralized, the team will allocate more tasks.
What are the drawbacks of System #3?
The main drawback is that this type of organization does not provide a great feedback loop for the team that develops the functionality. There are no incentives for those teams to produce quality code (as they are not the ones "seeing" and fixing those problems).
Another problem of this model is that it can't fully scale, as when a single team of 6-8 people has to maintain the code of 12+ teams, then there is too much complexity/know-how that they have to learn and keep up to.
System #4: Engineering Triage model
This option is an intermediate between System #0 and System #1. However, the triage/assignment of defects to each development team is done by a task force of engineers who know both the product and the team and can decide who to report it to.
This model aims to solve the problem of having a significant structure or complexity of development teams. At some point, having too many development teams might make it harder for support engineers to understand which team to report the ticket to. When a product is big enough, even if the support team is knowledgeable, they won't be able to learn the whole product and will need help to triage some of the tickets.
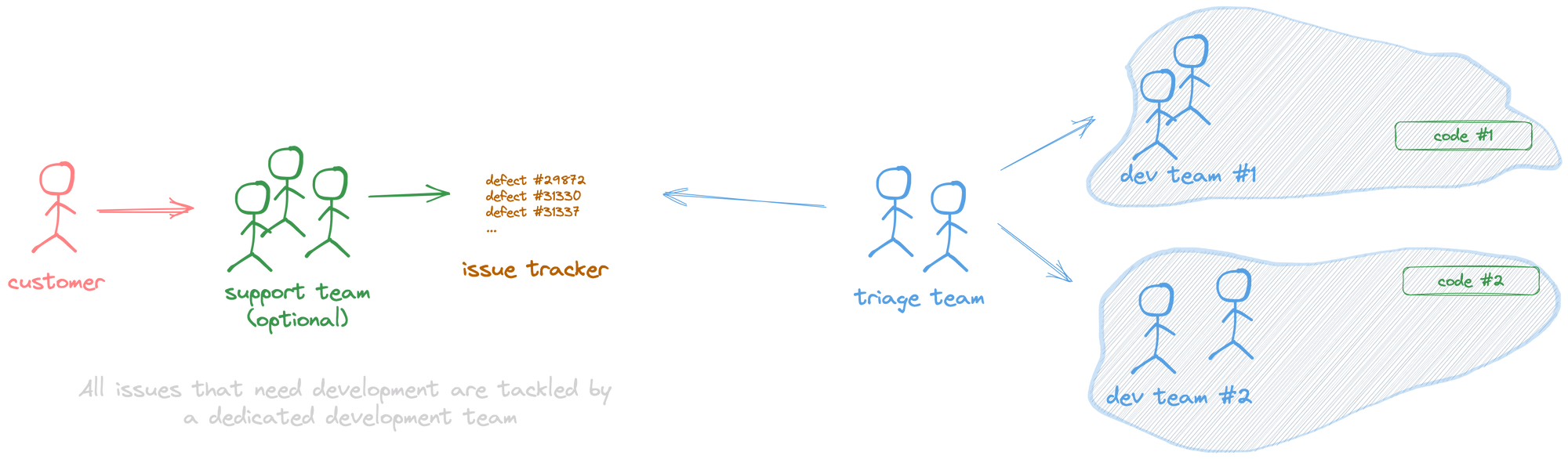
What's good about System #4?
Essentially, you get all the good stuff about System #1. Additionally, it addresses the problem of having the support team members learn that the whole product not being scalable.
What's not great about System #4?
The main downside is that an issue is queued two times (if having a support team) before it reaches the people who can fix it, taking more time to resolve it.
Final observations
Ok, what's the point of this article? Is there a system that's better than the rest? Having worked with them all, I do not think a perfect system exists. Each model produces their own incentives and makes it easier to achieve X variables (cost, time to resolve an issue, etc.) at the expense of one or other variables. I also think that companies may need to try and polish different systems at different organizational scales depending on what they need to optimize for.
Follow me on Twitter for more articles on troubleshooting software engineering teams' problems.
